
How Data Science Helps Power Worldwide Delivery of Netflix Content
Have you ever wondered where your video comes from when you watch Netflix? We serve video streams out of our own content delivery network (CDN), called Open Connect, which is tailored to one specific application: delivering internet TV to our members around the world. This system is the cornerstone of every Netflix video experience — serving 100% of our video, over 125 million hours every day, to 100 million members across the globe! In this post, we introduce some of the challenges in the content-delivery space where our data science and engineering teams collaborate to optimize the Netflix service.
In order to provide the best video experience to all of our members — with peak traffic of several tens of terabits per second — Open Connect deploys and operates thousands of servers, which we call Open Connect Appliances or OCAs, throughout the world. These OCAs are deployed at internet exchange locations where internet service providers (ISPs) can connect with us and are also offered to ISP partners to embed in their own networks. Embedded appliances can serve a large fraction of the Netflix traffic requested by an ISP’s customers. This architecture benefits ISPs by reducing cost and relieving internet congestion, while providing Netflix members with a high quality, uninterrupted viewing experience.
For more detail on how Open Connect works, check out this blog post.
Challenges for the Data Science Team
Our data scientists work to optimize the streaming quality of experience (QoE) by bringing a rigorous mathematical and statistical approach to algorithm and model development. To address some of the key data science problems in the rapidly growing content delivery space, we are building a new team focused on Content Delivery Network Science & Algorithms. The next sections introduce some of the high-level focus areas for this team.
Popularity Prediction and Content Caching
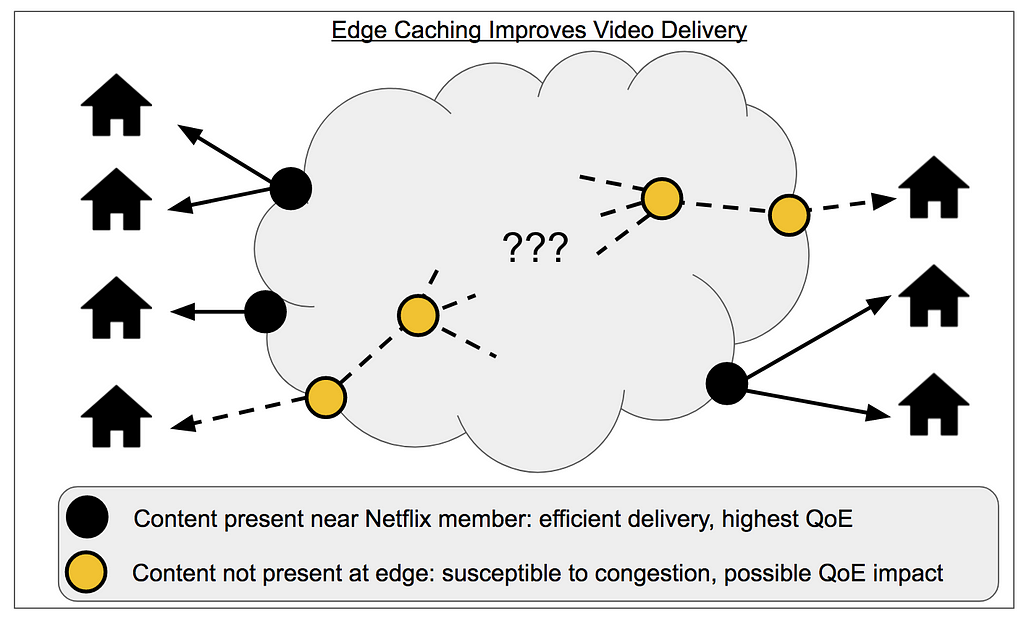
An important priority for Open Connect is to serve traffic from locations as close as possible to the end user and consequently to send as few bytes as possible across the wider internet — this is a little like designing a city where everyone lives near where they work to prevent cross-town traffic congestion. Because our video catalog is too large to store everything at all locations, we need to pre-position the most popular video files at the locations where they are most likely to serve nearby user requests. These techniques are known as edge caching.
In order to fully utilize the hardware capacity of our network for serving video during peak (primetime) viewing hours, we proactively cache content. That is, we forecast what will be popular tomorrow and only use disk and network resources for filling during quiet, off-peak hours (this blog post gives more details on how we fill content). This optimization is possible because our robust data on content popularity gives us enough signal to forecast daily demand with high fidelity.

From the data science perspective, our goal is to accurately predict popularity and also to use these predictions to prioritize content updates. The prioritization objective is to simultaneously cache the most popular content but also minimize the number of file replacements to reduce fill traffic. For content placement, we do not need to predict popularity all the way to the user level, so we can take advantage of local or regional demand aggregation to increase accuracy. However, we need to predict at a highly granular level in another dimension: there can be hundreds of different files associated with each episode of a show so that we can provide all the encoding profiles and quality levels (bitrates) to support a wide range of devices and network conditions. We need separate predictions for each file because their size and popularity, therefore their cache efficiency, can vary by orders of magnitude.
Our work in this area is a combination of time series forecasting, constrained optimization, and high-level network modeling, and our ongoing challenge is to adapt our algorithms to the dynamics of global member preferences, evolving network conditions, and new markets.
Optimizing Content Allocation within Clusters
After we use popularity prediction to decide what content to cache at each location, an important related area of data science work is to optimize the way files are distributed within a cluster of OCAs to maximize hardware utilization. We group OCAs into clusters that function together as logical units for storing content and serving user video requests. If an OCA in a cluster becomes unhealthy — due to traffic overload or any other operational issue — some traffic is steered to an alternative location. Because an imbalance in the traffic served by one machine in a cluster can become a “weak link” with respect to overall health of the cluster, it is important to maintain a balanced traffic load across the individual appliances within a cluster.
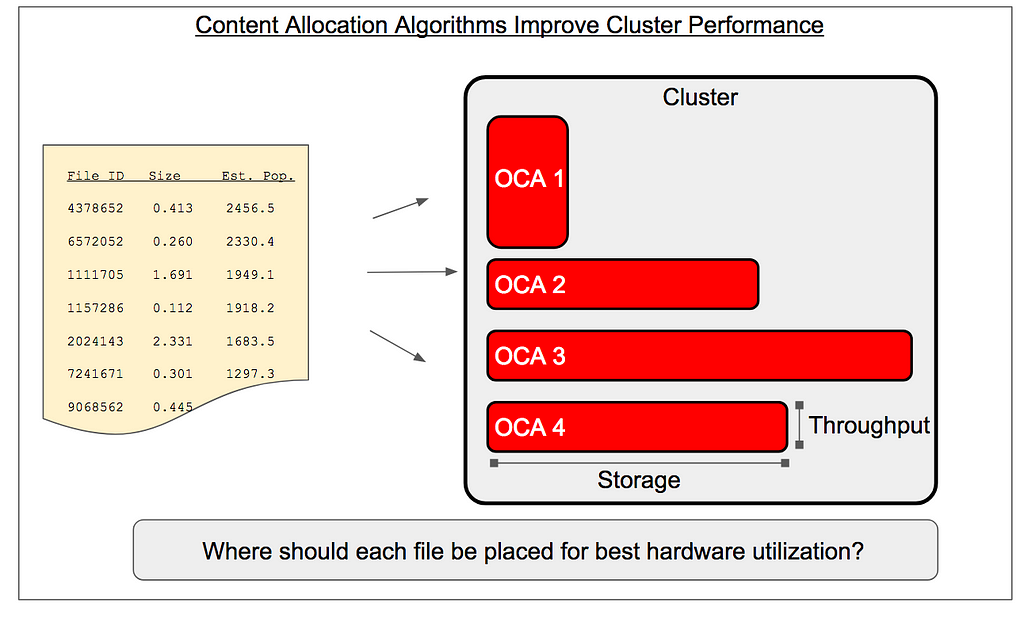
Cluster performance can be addressed at several layers, including through development of new allocation algorithms for placing content into clusters. A simple way to see how content allocation affects performance is to imagine a bad algorithm that places too much highly popular content on one server — this server will quickly saturate when the other servers are not doing much work at all. To avoid this situation, we distribute content pseudo-randomly, but in a stable and repeatable way (based on consistent hashing). However, content placement with any degree of randomness can still lead to “hot spots” of anomalously high load — a phenomenon exacerbated by power-law traffic patterns or by heterogeneous clusters of different hardware types.
We’re working on alternative content distribution algorithms that provide stable and repeatable placement, but are tailored to specific clusters to reduce load imbalance and maximize hardware utilization. Our work in this area involves constrained optimization — servers have finite capacity for both storage and network throughput — and a healthy dose of probability and statistics to model the fluctuations in traffic served under a given allocation algorithm.
Long-Term Capacity Planning
Netflix moves fast, and Open Connect is a highly dynamic system. Planning for changes is an important challenge for many teams across the company. Some of the many phenomena that can change the system behavior are catalog changes (new content on the service), member growth, encoding advances, and a dynamic consumer electronics ecosystem (for example, increasing adoption of 4K TVs or growth in mobile usage around the world). Each of these factors can affect how much traffic is served from a network location, as well as how efficiently a cache of fixed size can offload traffic or what hardware designs may be most effective in the future.
One of our data science challenges is to combine these various factors into medium- and long-term forecasts to inform capacity planning. Where should additional servers be deployed in anticipation of traffic growth and efficiency changes a year from now? This work involves a combination of demand forecasting, system modeling — combining top-level factors together into a performance model — and resource analysis to identify areas of under- or over-utilization now and in the future.
Interested in Working With Us?
The descriptions above are of current projects, but many more challenges lie just around the corner as our service grows globally, and we continue the close collaboration between Science & Algorithms and Open Connect. Our work is evolving rapidly as we continue to invent the technology of internet television here at Netflix. Our new CDN Science & Algorithms team is dedicated to tackling these problems, and we are on the lookout for strong practitioners in statistics, applied mathematics, and optimization to join us!
How Data Science Helps Power Worldwide Delivery of Netflix Content was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
