
To Be Continued: Helping you find shows to continue watching on Netflix
Introduction
Our objective in improving the Netflix recommendation system is to create a personalized experience that makes it easier for our members to find great content to enjoy. The ultimate goal of our recommendation system is to know the exact perfect show for the member and just start playing it when they open Netflix. While we still have a long way to achieve that goal, there are areas where we can reduce the gap significantly.
When a member opens the Netflix website or app, she may be looking to discover a new movie or TV show that she never watched before, or, alternatively, she may want to continue watching a partially-watched movie or a TV show she has been binging on. If we can reasonably predict when a member is more likely to be in the continuation mode and which shows she is more likely to resume, it makes sense to place those shows in prominent places on the home page.
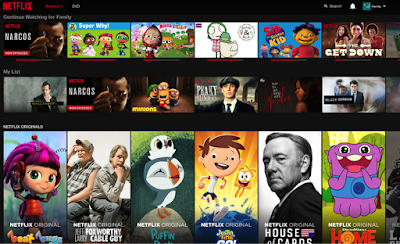
While most recommendation work focuses on discovery, in this post, we focus on the continuation mode and explain how we used machine learning to improve the member experience for both modes. In particular, we focus on a row called “Continue Watching” (CW) that appears on the main page of the Netflix member homepage on most platforms. This row serves as an easy way to find shows that the member has recently (partially) watched and may want to resume. As you can imagine, a significant proportion of member streaming hours are spent on content played from this row.
Continue Watching
Previously, the Netflix app in some platforms displayed a row with recently watched shows (here we use the term show broadly to include all forms of video content on Netflix including movies and TV series) sorted by recency of last time each show was played. How the row was placed on the page was determined by some rules that depended on the device type. For example, the website only displayed a single continuation show on the top-left corner of the page. While these are reasonable baselines, we set out to unify the member experience of CW row across platforms and improve it along two dimensions:
-
Improve the placement of the row on the page by placing it higher when a member is more likely to resume a show (continuation mode), and lower when a member is more likely to look for a new show to watch (discovery mode)
- Improve the ordering of recently-watched shows in the row using their likelihood to be resumed in the current session

Intuitively, there are a number of activity patterns that might indicate a member’s likelihood to be in the continuation mode. For example, a member is perhaps likely to resume a show if she:
-
is in the middle of a binge; i.e., has been recently spending a significant amount of time watching a TV show, but hasn’t yet reached its end
-
has partially watched a movie recently
-
has often watched the show around the current time of the day or on the current device
On the other hand, a discovery session is more likely if a member:
-
has just finished watching a movie or all episodes of a TV show
-
hasn’t watched anything recently
-
is new to the service
These hypotheses, along with the high fraction of streaming hours spent by members in continuation mode, motivated us to build machine learning models that can identify and harness these patterns to produce a more effective CW row.
Building a Recommendation Model for Continue Watching
To build a recommendation model for the CW row, we first need to compute a collection of features that extract patterns of the behavior that could help the model predict when someone will resume a show. These may include features about the member, the shows in the CW row, the member’s past interactions with those shows, and some contextual information. We then use these features as inputs to build machine learning models. Through an iterative process of variable selection, model training, and cross validation, we can refine and select the most relevant set of features.
While brainstorming for features, we considered many ideas for building the CW models, including:
-
Member-level features:
-
Data about member’s subscription, such as the length of subscription, country of signup, and language preferences
-
How active has the member been recently
-
Member’s past ratings and genre preferences
-
Features encoding information about a show and interactions of the member with it:
-
How recently was the show added to the catalog, or watched by the member
-
How much of the movie/show the member watched
-
Metadata about the show, such as type, genre, and number of episodes; for example kids shows may be re-watched more
-
The rest of the catalog available to the member
-
Popularity and relevance of the show to the member
-
How often do the members resume this show
-
Contextual features:
-
Current time of the day and day of the week
-
Location, at various resolutions
- Devices used by the member
Two applications, two models
As mentioned above, we have two tasks related to organizing a member’s continue watching shows: ranking the shows within the CW row and placing the CW row appropriately on the member’s homepage.
Show ranking
To rank the shows within the row, we trained a model that optimizes a ranking loss function. To train it, we used sessions where the member resumed a previously-watched show – i.e., continuation sessions – from a random set of members. Within each session, the model learns to differentiate amongst candidate shows for continuation and ranks them in the order of predicted likelihood of play. When building the model, we placed special importance on having the model place the show of play at first position.
We performed an offline evaluation to understand how well the model ranks the shows in the CW row. Our baseline for comparison was the previous system, where the shows were simply sorted by recency of last time each show was played. This recency rank is a strong baseline (much better than random) and is also used as a feature in our new model. Comparing the model vs. recency ranking, we observed significant lift in various offline metrics. The figure below displays Precision@1 of the two schemes over time. One can see that the lift in performance is much greater than the daily variation.

This model performed significantly better than recency-based ranking in an A/B test and better matched our expectations for member behavior. As an example, we learned that the members whose rows were ranked using the new model had fewer plays originating from the search page. This meant that many members had been resorting to searching for a recently-watched show because they could not easily locate it on the home page; a suboptimal experience that the model helped ameliorate.
Row placement
To place the CW row appropriately on a member’s homepage, we would like to estimate the likelihood of the member being in a continuation mode vs. a discovery mode. With that likelihood we could take different approaches. A simple approach would be to turn row placement into a binary decision problem where we consider only two candidate positions for the CW row: one position high on the page and another one lower down. By applying a threshold on the estimated likelihood of continuation, we can decide in which of these two positions to place the CW row. That threshold could be tuned to optimize some accuracy metrics. Another approach is to take the likelihood and then map it onto different positions, possibly based on the content at that location on the page. In any case, getting a good estimate of the continuation likelihood is critical for determining the row placement. In the following, we discuss two potential approaches for estimating the likelihood of the member operating in a continuation mode.
Reusing the show-ranking model
A simple approach to estimating the likelihood of continuation vs. discovery is to reuse the scores predicted by the show-ranking model. More specifically, we could calibrate the scores of individual shows in order to estimate the probability P(play(s)=1) that each show s will be resumed in the given session. We can use these individual probabilities over all the shows in the CW row to obtain an overall probability of continuation; i.e., the probability that at least one show from the CW row will be resumed. For example, under a simple assumption of independence of different plays, we can write the probability that at least one show from the CW row will be played as:

Dedicated row model
In this approach, we train a binary classifier to differentiate between continuation sessions as positive labels and sessions where the user played a show for the first time (discovery sessions) as negative labels. Potential features for this model could include member-level and contextual features, as well as the interactions of the member with the most recent shows in the viewing history.
Comparing the two approaches, the first approach is simpler because it only requires having a single model as long as the probabilities are well calibrated. However, the second one is likely to provide a more accurate estimate of continuation because we can train a classifier specifically for it.
Tuning the placement
In our experiments, we evaluated our estimates of continuation likelihood using classification metrics and achieved good offline metrics. However, a challenge that still remains is to find an optimal mapping for that estimated likelihood, i.e., to balance continuation and discovery. In this case, varying the placement creates a trade-off between two types of errors in our prediction: false positives (where we incorrectly predict that the member wants to resume a show from the CW row) and false negatives (where we incorrectly predict that the member wants to discover new content). These two types of errors have different impacts on the member. In particular, a false negative makes it harder for members to continue bingeing on a show. While experienced members can find the show by scrolling down the page or by using the search functionality, the additional friction can make it more difficult for people new to the service. On the other hand, a false positive leads to wasted screen real estate, which could have been used to display more relevant recommendation shows for discovery. Since the impacts of the two types of errors on the member experience are difficult to measure accurately offline, we A/B tested different placement mappings and were able to learn the appropriate value from online experiments leading to the highest member engagement.
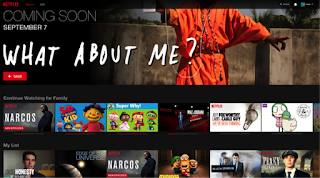
Context Awareness
One of our hypotheses was that continuation behavior depends on context: time, location, device, etc. If that is the case, given proper features, the trained models should be able to detect those patterns and adapt the predicted probability of resuming shows based on the current context of a member. For example, members may have habits of watching a certain show around the same time of the day (for example, watching comedies at around 10 PM on weekdays). As an example of context awareness, the following screenshots demonstrate how the model uses contextual features to distinguish between the behavior of a member on different devices. In this example, the profile has just watched a few minutes of the show “Sid the Science Kid” on an iPhone and the show “Narcos” on the Netflix website. In response, the CW model immediately ranks “Sid the Science Kid” at the top position of the CW row on the iPhone, and puts “Narcos” at the first position on the website.

Serving the Row
Members expect the CW row to be responsive and change dynamically after they watch a show. Moreover, some of the features in the model are time and device dependent and can not be precomputed in advance, which is an approach we use for some of our recommendation systems. Therefore, we need to compute the CW row in real-time to make sure it is fresh when we get a request for a homepage at the start of a session. To keep it fresh, we also need to update it within a session after certain user interactions and immediately push that update to the client to update their homepage. Computing the row on-the-fly at our scale is challenging and requires careful engineering. For example, some features are more expensive to compute for the users with longer viewing history, but we need to have reasonable response times for all members because continuation is a very common scenario. We collaborated with several engineering teams to create a dynamic and scalable way for serving the row to address these challenges.
Conclusion
Having a better Continue Watching row clearly makes it easier for our members to jump right back into the content they are enjoying while also getting out of the way when they want to discover something new. While we’ve taken a few steps towards improving this experience, there are still many areas for improvement. One challenge is that we seek to unify how we place this row with respect to the rest of the rows on the homepage, which are predominantly focused on discovery. This is challenging because different algorithms are designed to optimize for different actions, so we need a way to balance them. We also want to be thoughtful about pushing CW too much; we want people to “Binge Responsibly” and also explore new content. We also have details to dig into like how to determine if a show is actually finished by a user so we can remove it from the row. This can be complicated by scenarios such as if someone turned off their TV but not the playing device or fell asleep watching. We also keep an eye out for new ways to use the CW model in other aspects of the product.
Can’t wait to see how the Netflix Recommendation saga continues? Join us in tackling these kinds of algorithmic challenges and help write the next episode.
