
Developer Experience Lessons Operating a Serverless-like Platform at Netflix
Developer Experience Lessons Operating a Serverless-like Platform At Netflix
By Vasanth Asokan, Ludovic Galibert and Sangeeta Narayanan
The Netflix API is based on a dynamic scripting platform that handles thousands of changes per day. This platform allows our client developers to create a customized API experience on over a thousand device types by executing server side adapter code in response to HTTP requests. Developers are only responsible for the adapter code they write; they do not have to worry about infrastructure concerns related to server management and operations. To these developers, the scripting platform in effect, provides an experience similar to that offered by serverless or FaaS platforms. It is important to note that the similarities are limited to the developer experience (DevEx); the runtime is a custom implementation that is not designed to support general purpose serverless use cases. A few years of developing and operating this platform for a diverse set of developers has yielded several DevEx learnings for us. Here’s our biggest takeaway:
In serverless, a combination of smaller deployment units and higher abstraction levels provides compelling benefits, such as increased velocity, greater scalability, lower cost and more generally, the ability to focus on product features. However, operational concerns are not eliminated; they just take on new forms or even get amplified. Operational tooling needs to evolve to meet these newer requirements. The bar for developer experience as a whole gets raised.
This is the first in a series of posts where we draw from our learnings to outline various aspects that we are addressing in the next generation of our platform. We believe these aspects are applicable to general purpose serverless solutions too. Here we will look at application development, delivery and code composition. Future posts will delve into topics such as deployments, insights, performance, scalability and other operational concerns.
Development
How effortless is the local development experience?
Our scripting platform allows developers to write functions that contain application logic. Developers upload their code (a script) to the scripting platform which provides the runtime and also handles infrastructure concerns like API routing and scaling. The script is addressable via an HTTP route (aka endpoint) defined by the developer and executes on a remote VM.
By definition, a remote runtime model prevents the user’s script from being executable locally, which adds a lot of friction to the develop-test iterations. Even if local changes are somehow seamlessly deployed, turnaround time (even if only a few tens of seconds) is extremely painful for developers.
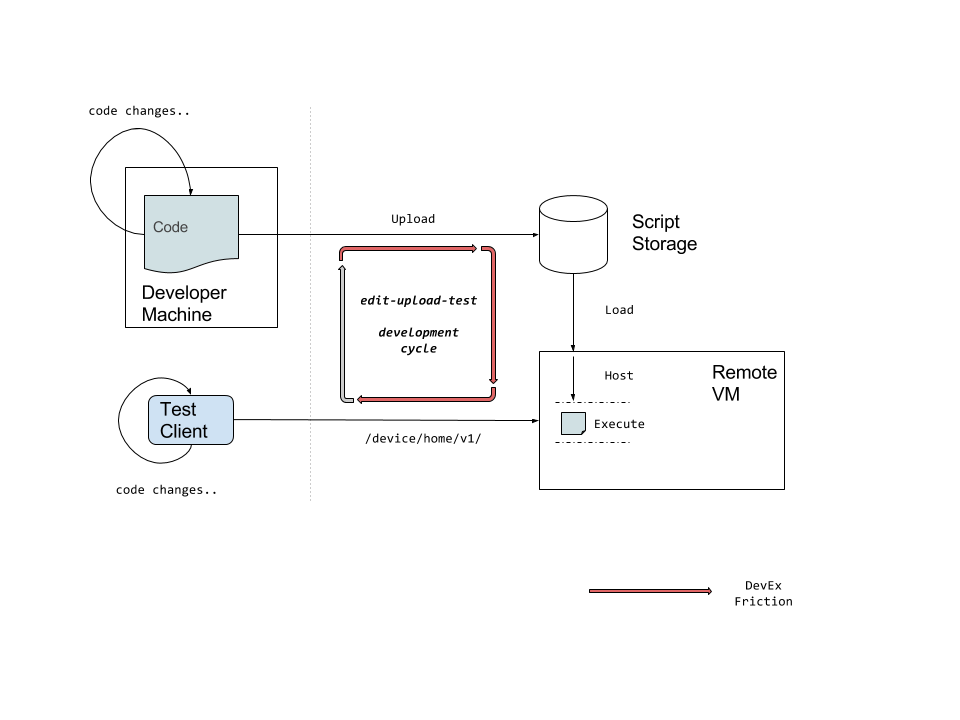
To alleviate this, we have a cloud-based REPL for interactive exploration and execution of scripts. However, we observe that scripts are rarely simple functional units. Over time they tend to become more like nano-services with logic spread across multiple modules and source files — a REPL simply does not scale for real production scripts. Nor does it cover requirements such as supporting a user’s preferred IDE or allowing debugging via breakpoints.
We also notice anti-patterns starting to creep-in — developers favor verbose debug logging or other defensive measures just to avoid upload iterations. This also introduces risks like accidental exposure of sensitive data in debug logs. These experiences have led us to prioritize a first class, low latency local development experience with support for live-reload, debugging and emulating the cloud execution environment for the next generation of our platform.
Packaging & Versioning
Are deployment artifacts portable, easy to version and manage?
In our current platform, we focus on three aspects of deployment artifacts
- Providing a “build once, deploy anywhere” model
- Enabling simple addressability
- Facilitating traceability and lifecycle management
Portable, immutable artifacts are necessary in order to ensure that code behaves consistently across environments and can be promoted to production with confidence. Since our platform runs on the JVM, a JAR file was the obvious choice to achieve this.
Once built, an artifact needs to be addressable in any environment as it makes its way through the delivery pipeline from lower level environments all the way through to production. The simplest scheme we found was to use a name and an optional version. Given the name and version, any environment or region can address the artifact and serve up the script for execution. While it sounds simple, a human readable naming model frees users up from having to work with opaque system generated resource identifiers that are harder to reason about.
We also attach rich metadata to the artifact that includes things like runtime (e.g. Java version), TTL, SCM commit and more. Such metadata powers various use cases. For instance the commit pointer enables traceability of source code across releases and environments and also enables automating upgrade flows. Proactively including such metadata helped unlock solutions to use cases such as lifecycle management of resources, that are unique to serverless.
Overall our approach works well for our users, but as with every technology, things sometimes end up being used in ways that vary significantly from the original intent. As an example, since we made version optional, we saw a pattern of teams crafting custom versioning schemes into their resource names, thus unnecessarily reinventing the wheel. Our re-architecture efforts address this in a couple of ways:
- Versioning has been elevated into a first-class concept based on the well understood notions of semantic versioning in our re-architecture efforts.
- The use of Docker for packaging helps guarantee immutability and portability by bundling in system dependencies. Going back to the earlier section on local development, it also provides developers the ability to run a production script and locally in a bit loyal way.
Testing and CI
What are the implications of increased development velocity?
It is extremely easy to deploy code changes in our platform and we certainly see developers leverage this capability to its fullest extent. This in turn highlights a few stark differences between pre-production and production environments.
As an example, frequent developer commits coupled with CI/CD runs result in nearly 10x greater deployment velocity in pre-production environments. For every 10 to 20 test deployments, only one might make it into production. These test deployments are typically short-lived, but they create a maintenance burden for developers by leaving behind a trail of unused deployments that need to be cleaned up to conserve resources.
Another difference is that the volume of traffic is vastly lower than in production. In conjunction with short-lived deployments, this has the unfortunate effect of aggravating cold start issues for the script. As a result, development and test runs often trip over unpredictable execution latencies, and it becomes hard to tune client timeouts in a consistent way. This leads to an undesirable situation where developers rely on production for all their testing, which in turn defeats isolation goals and leads to tests eating into production quotas.
Finally, the remote execution model also dictates that a different set of features (like running integration tests, generating code coverage, analyzing execution profiles etc.) are required in pre-production but risky or not viable in production.
Given all this, the key learning is to have well defined, isolated and easy to use pre-production environments from the get-go. In the next generation of our platform we are aiming to have the pre-production experience be on par with production, with its own line of feature evolution and innovation.
Code modularity and composition
Can fine-grained functions be composed rapidly with confidence?
As adoption of our scripting platform grew, so did the requirement for reusing code that implemented shared functionality. Reusing by copy pasting scales only to a certain extent and adds extra operational costs when changes are needed to a common component. We needed a solution to easily compose loosely coupled components dynamically, while providing insight into code reuse. We achieve this by first-classing the notions of dynamic shared libraries and dependency management, coupled with the ability to resolve and chain direct and transitive dependencies at runtime.
A key early learning here is that shared module producers and consumers have differing needs around updates. Consumers want tight control over when they pick up changes, while providers want to be highly flexible and decoupled from consumers in rapidly pushing out updates.
Using semantic versioning to support specification and resolution of dependencies helps support both sides of this use case. Providers and consumers can negotiate a contract according to their preferences by using strict versions or semantic version ranges.
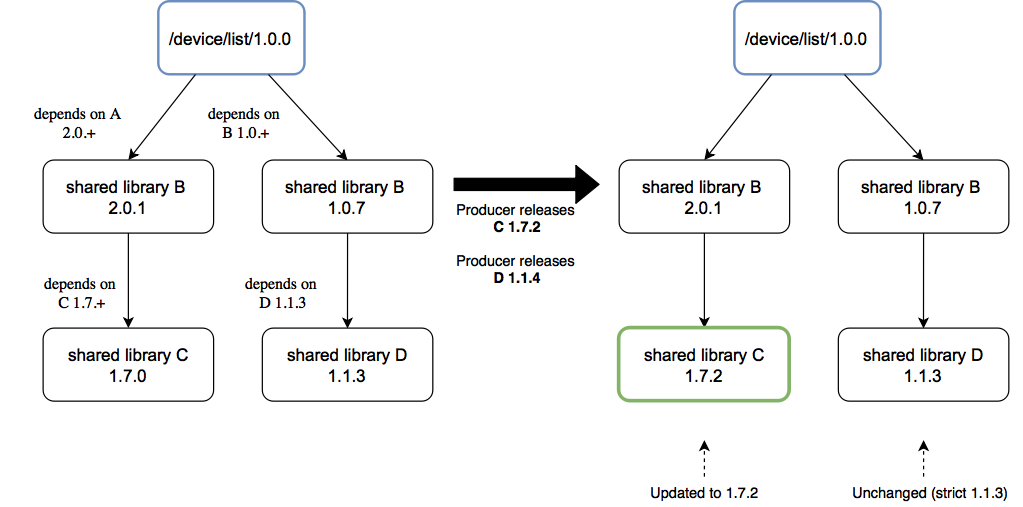
In such a loosely coupled model, sustaining the rate of change at scale requires the ability to gain insight into the dependency chain in both directions. Our platform provides consumers and providers the ability to track updates to shared modules they depend on or deliver.
Here’s how such insights help our users:
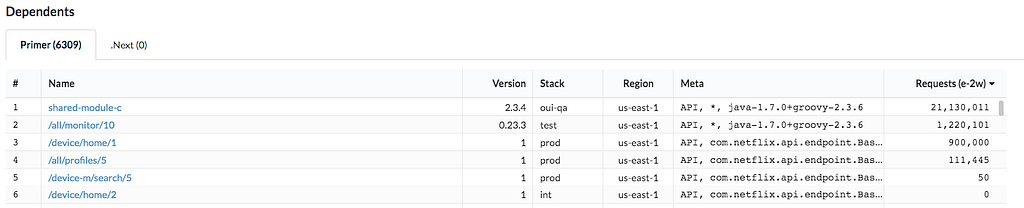
- Shared module providers can track the uptake of bug fixes or feature updates.
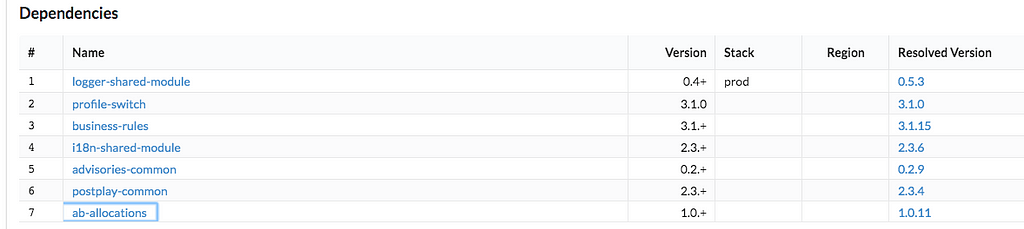
- Consumers can quickly identify which version of which dependencies they are using and if they need to upgrade.
- They enable better lifecycle management (to be covered in a later post). Shared code needs to be maintained as long as a consumer is using it. If a version range (major and/or minor) is no longer in use, it can be sunset and system resources freed up for other uses.
Up Next
In a future post, we will take a look at operational concerns. Stay tuned!
Developer Experience Lessons Operating a Serverless-like Platform at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
